

From 4H Renders to 90S Freedom | N4D Production-Ready AI 3D Assets
If you’ve ever been a senior 3D artist or led a game development team, you know the exhaustion that sets in during those long nights.
You’re staring at a screen, squinting at an industrial valve model, trying to strip “dead shadows” out of the texture map. Three days into working on this one asset, your project manager is pacing nearby, waiting for the model to clear physics collision testing in Unity so the team can move forward. This repetitive, high-pressure, low-value labor is the silent killer of creative morale.
For years, we were told that Generative AI would be the solution. But early attempts by tech giants like Google required nearly 4 hours of compute time for a single model. In a professional production pipeline, that’s not automation. It’s a bottleneck.
Later, the academic world introduced the LRM (Large Reconstruction Model) paradigm. While researchers like Kai Zhang successfully compressed the timeline to 30 minutes, this approach left us with “visual shells.” These models didn’t understand their own internal structures and were plagued by baked-in lighting.
Today, the era of blind guessing is over.
Table of Contents
1. Why Early AI 3D Models Failed the Production Test: Missing Production-Ready Topology
In the past year, if you’ve experimented with off-the-shelf AI 3D tools, you likely found the outputs unusable for professional engines. This usually boils down to two problems that drive developers crazy:
- The Dead Shadow Problem: Most AI models are trained on 2D images, making them unable to distinguish between the actual color of an object and the shadows cast by light sources. The result? Shadows “welded” onto the texture. When you drop that asset into a game with dynamic lighting, it looks like a cheap, broken sticker.
- Structural Illiteracy: These tools are essentially guessing what the back of an object looks like. They produce “thin shells” with no internal logic, no thickness, and no watertight integrity. They aren’t 3D models. They’re 3D illusions.
Neural4D operates on a fundamentally different logic.

2. Spatial Sparse Attention: Giving AI a Native 3D Soul
The secret to our 90-second delivery and physical accuracy lies in abandoning the inefficient “2D-to-3D guessing” path.
As discussed in Decoding Direct3D-S2 Architecture, Neural4D (N4D) uses native volumetric generation. The engine behind this speed is our proprietary Spatial Sparse Attention (SSA) mechanism.
Traditional AI wastes massive amounts of compute power processing empty space. Our SSA mechanism acts like a master architect, focusing only on the “tokens” that actually have geometric meaning.
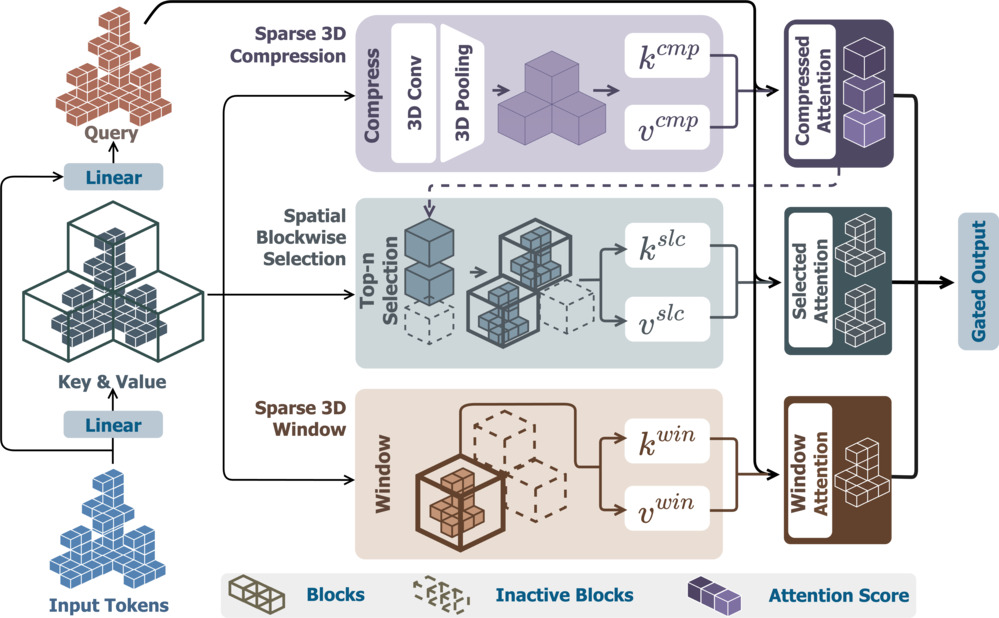
✅ 9.6x Acceleration: During backpropagation, SSA achieves nearly 10x speed improvements over standard models.
✅ The Resolution Threshold: This allows us to run 2048³ resolution models on just 8 GPUs, a feat that requires 32 GPUs for our competitors.
Because we calculate Native Volume directly via SSA, our models are born with complete physical structures. The AI doesn’t guess the back. It constructs it. This is why you’ll never find a “dead shadow” in a Neural4D asset.
3. The Self-Evolving Flywheel: N4D’s Proprietary Data Engine
You might wonder how we trained this level of intelligence given that high-quality 3D data is globally scarce.
This is where I take the most pride in our “Self-Evolving Data Engine.” We stopped searching the internet for messy, shadow-filled datasets. Instead, we built a closed-loop system.
- AI Synthetic Data System: We use procedural systems to generate millions of mathematically perfect, physically accurate synthetic 3D models. These models have zero shadows and pure PBR materials. They represent “Ground Truth.”
- Generative Training: We feed this “Truth” into our Direct3D-S2 framework. When an AI sees a million perfect industrial structures, it learns the inherent laws of geometry and light.
- The Direct AI Loop: This high-quality generation capability feeds back into the system, constantly iterating. This flywheel allowed us to leap from the 30-minute LRM standard to the 90-second Neural4D industrial standard.
4. 2026: From Cost Anxiety to Creative Explosion
By 2026, the global generative 3D market will be at an inflection point. If you’re still manually retopologizing meshes or fixing shadows, you’re losing your competitive edge.
Imagine what happens to your workflow when you integrate the Text to 3D API:
👉 The ROI Shift: At approximately $0.15 per call, the cost of asset creation moves toward zero. Compare that to the hundreds of dollars spent outsourcing a single prop.
👉 Engine-Ready Assets: The output is a manifold, watertight mesh. This means it’s ready for immediate physics simulation, fluid dynamics, or even direct 3D printing.
Whether you’re an indie developer or a digital transformation lead, this is your chance to stop being a “digital stone-cutter” and return to being a creator.
5. Frequently Asked Questions (FAQ)
Q: How does Neural4D achieve 90-second generation when Google DreamFusion takes 4 hours?
A: The difference lies in the architecture. Google’s DreamFusion relies on Score Distillation Sampling (SDS), which requires thousands of slow iterations to “distill” a 3D object. Neural4D uses the Direct3D-S2 architecture with Spatial Sparse Attention (SSA). This allows us to generate the native 3D volume in a single forward pass, rather than iteratively guessing, reducing computation time by nearly 160x.
Q: Will the generated assets have “baked-in” lighting or shadows?
A: No. Unlike diffusion-based models that project 2D images (carrying shadows) onto 3D shapes, Neural4D generates Native 3D Volumes. We calculate the Albedo (color), Roughness, and Metallic channels independently. The result is a clean PBR asset with no directional lighting, ready for any dynamic lighting environment in Unity or Unreal Engine.
Q: Are the models “watertight” for 3D printing or physics simulation?
A: Yes. Because Neural4D understands volume, not just surface appearance, it generates manifold, watertight geometry. There are no holes or non-manifold edges. You can drop these assets directly into a physics engine for collision testing or slice them for 3D printing without manual repair.
Q: How does Neural4D handle copyright and IP issues with training data?
A: We use a proprietary Self-Evolving Synthetic Data Engine. Our models are trained primarily on procedurally generated, mathematically perfect 3D data, not on scraped, copyrighted artwork from the internet. This provides a clean IP lineage for enterprise use.
Q: What file formats are supported for export?
A: We support the industry standards: .obj (universal), .fbx (for game engines/animation), .glb (for web/AR), .usdz (for Apple ecosystem), .stl (for manufacturing), and .blend (for Blender).
6. Conclusion
Efficiency is not just about doing things faster. It’s about making the impossible, possible.
If you’re currently staring at a project roadmap that requires thousands of unique assets, do not despair over the timeline.
For large-scale enterprise projects or massive asset library migrations, contact us at https://www.neural4d.com/contact to discuss high-volume pricing and custom integration.



