

Spatial Intelligence & the Shift Toward Production-Ready 3D AI
If you have been following the evolution of 3D AI, you already know something feels off.
Over the past two years, the industry has celebrated rapid visual breakthroughs. Diffusion-based models learned how to generate convincing shapes. Tools like Rodin (Hyper3D) delivered striking surfaces. Others pushed speed to the extreme, producing meshes in seconds. In many demos, AI has already passed the visual Turing test.
Yet for developers, researchers, and technical teams, one truth remains unchanged.
Looking correct is not the same as being usable.
The real competition in 3D AI is no longer about visual fidelity. It is about Spatial Intelligence: the ability for a system to understand physical structure, geometry, and interaction, not just appearance.
As Fei-Fei Li has emphasized in her work on spatial intelligence, the next generation of AI must move beyond pixels and toward reasoning about the physical world itself.
Table of Contents
Part 1. From Pixel Guessing to Volumetric Reasoning
Most early 3D generation systems inherited their logic from 2D diffusion models.
They learned how objects look from multiple angles, but not how objects are built. When asked to generate a chair, these systems effectively painted a chair in space rather than constructing one. This design choice explains two persistent failures across the industry.
First, baked lighting artifacts. Shadows from training images become fused into textures, creating assets that break under real-time lighting.
Second, structural illiteracy. Many models produce thin shells with no thickness, internal logic, or watertight geometry. These outputs may look impressive in isolation, but they fail immediately inside physics engines, simulation pipelines, or production workflows.
Neural4D deliberately chose a more difficult path: native volumetric generation.
Instead of reconstructing 3D from images, Neural4D treats volume as a first-class data representation. This approach aligns with the academic shift toward Large Reconstruction Models, where geometry is learned as structure rather than inferred as appearance.
At the core of this system is Spatial Sparse Attention (SSA).
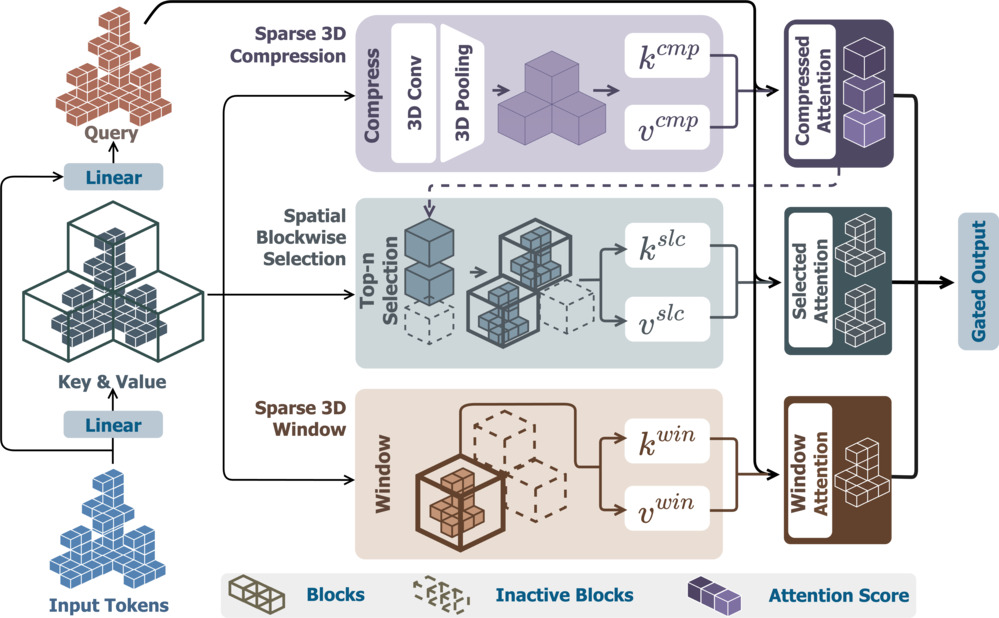
SSA allows the model to focus computation only on regions that carry geometric meaning. Empty space is ignored. Structural continuity is enforced early, not repaired later. In practice, this enables high-resolution volumetric reasoning without brute-force computing.
The result is not a visual shell, but a physically coherent object.
Part 2. The Global 3D AI Landscape in 2026
As the field matures, the strategic boundaries are becoming clearer.
Some organizations pursue scale through compute. Foundation models backed by massive GPU clusters aim to generate everything, prioritizing universality and ecosystem control.
Others optimize for speed. Rapid prototyping tools function as sketchpads, ideal for early ideation when precision does not matter.
Neural4D occupies a different position.
It optimizes for production certainty.
Rather than asking how fast a mesh can appear on screen, the system asks whether that mesh can survive contact with a real pipeline. Clean topology. Stable normals. Valid physical volume. Assets that import directly into engines without repair.
If you need a single visual asset for a presentation, many tools can help.
If you need thousands of interactable components for simulation, robotics, or large-scale environments, certainty becomes the bottleneck. This is the problem Neural4D is built to solve.
Part 3. Why Production-Ready Geometry Changes Everything
In production environments, geometry errors compound.
A single non-manifold edge can break physics simulations.
Baked shadows can invalidate dynamic lighting.
Inconsistent topology blocks automation and scaling. Production-ready 3D AI assets eliminate these failure points upstream.
By generating watertight, structurally valid geometry by default, Neural4D allows teams to treat 3D generation as infrastructure rather than experimentation. Assets move directly into engines, simulations, or downstream processing without human cleanup.

This shift has a compounding effect. When geometry is reliable, pipelines become programmable. When pipelines are programmable, scale becomes achievable.
Part 4. From Static 3D to 4D Dynamics
The rise of high-quality video generation has raised an understandable question.
If video models can simulate reality convincingly, do we still need 3D?
The answer lies in interaction.
Video represents appearance over time.
3D represents structure.
4D represents structure evolving through time under physical constraints. Neural4D‘s internal roadmap already extends beyond static assets toward time-evolving geometry. The goal is not simply to generate a leopard, but to generate an entity that understands joints, motion, balance, and force.
This transition from static objects to dynamic systems is essential for world models and embodied AI. A system that can generate infinite, physically valid scenarios becomes a training ground for intelligence itself.
Not a simulation of reality, but a framework for reasoning about it.
Part 5. Building Infrastructure, Not Illusions
Spatial Intelligence is not a feature. It is a foundation.
As the industry moves from research demonstrations to real-world deployment, the limitations of visually driven 3D AI become impossible to ignore. Systems that do not understand volume cannot reason about physics. Systems that do not reason about physics cannot scale into production.
Neural4D is not designed to perform visual tricks.
It is designed to build the underlying infrastructure for the next era of 3D AI: from volumetric reasoning, to production-ready assets, to dynamic, time-aware worlds.
From illusion to structure.
From pixels to physics.
From 3D to 4D. The race for Spatial Intelligence has only just begun.



